这篇文章会按这样的顺序来简单介绍raft算法:
第一部分
- 从整体上看raft算法是基于怎样的context(原论文的词汇,我的理解其实就是类似与数据结构一样的东西),即 replicated state machine上运行
- 假设在没有任何异常情况(没有任一一个节点挂掉,没有网络故障,所有节点的log正常插入,且follower与leader一致)下的集群是怎样运转的。
在进入第二部分之前,会简单介绍raft中的基础概念和基础结构
第二部分将会把假设的理想情况,即没有任何异常的条件去掉,看看在有节点异常挂掉或者由网络故障导致的节点失联,或者有节点之前挂掉后重连,结果log与leader的log有冲突的情况下,raft算法会怎样工作,其实主要是靠:
- leader election
- log replication
第三部分会基于第二部分继续探究,这样raft是不是就能确保一致性了呢?No,No,No,其实还没有,所以这部分会探讨safety:
election restriction
committing entries from previous terms
safety argument
follower and candidate crashes
timing and availability
第四部分cluster membership changes
第五部分Log compaction
1. Overview
raft是一个解决日志一致性和分区容错的算法。这个算法依赖于replicated state machine这个数据结构,而replicated state machine本身也由这样三部分构成:
- log
- consensus module
- state machine
当replicated state machine被多个服务器部署后,将可以使用raft算法来保证服务器间数据的一致性。
在说明replicated state machine三个子模块之前,先简单介绍一下raft算法的大致设计。在raft算法的设计中,每个replicated state machine都将在follower, candidate,leader中扮演一个角色。正常情况下,只有follower和leader。
先描述没有任何异常情况发生的情景
如下图所示: 初始化过程:当新部署一个raft集群,集群上的每个节点会因为在election timeout时间内没有接收到heart beat而开始leader election,直至选出一个leader为止。
过程1: client向leader所属的服务器发送请求(如果请求的是follower服务器,请求也会被转到leader上)
过程2:leader自己也会将请求中的数据插入log中,同时leader中的consensus module会通过appendEntriesRpc将数据和leader log 当前最大的index(这个在log replication会细说)发送给follower节点
过程3:follower节点收到数据后,将数据插入log中
过程4:follower节点更新state machine`
过程5:follower节点更新好state machine后,向leader发送response,告诉它我已经更新好了(当然,异常情况下,就不会发)
过程6:当leader发现大多数follower都已插入log,并将这个数据更新到state machine时,leader就会更新自己的state machine。
过程7:leader会返回给client一个response,告诉它操作成功了
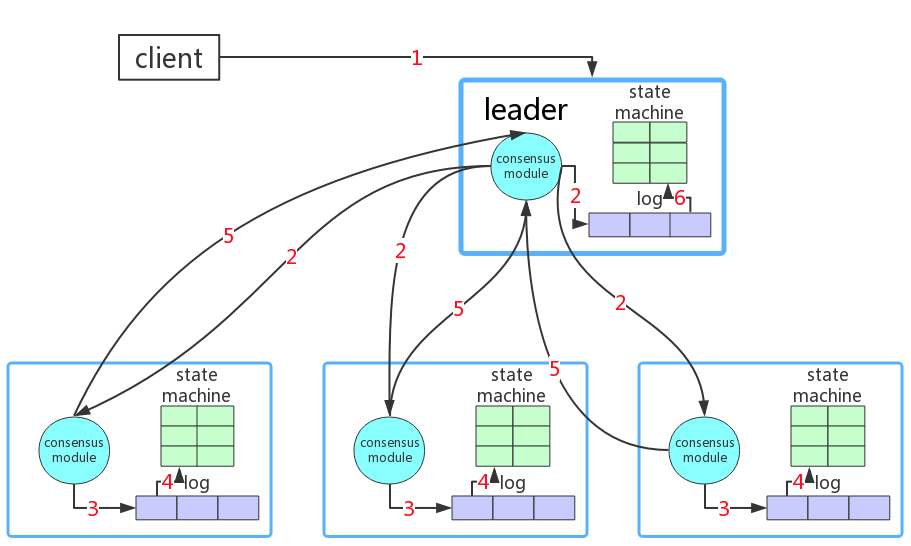
这样,整个集群上的数据就都是一致的了。这是在理想环境下的raft执行流程,但raft的并不是只能在这样的环境下才能运行的。