序
replication是一系列的通信问题
- 怎样的排列顺序和模式才能提供好的性能和可用性?
- 在网络分区故障发生时,如何容错呢?
通信模型
通常,通信模式会有两种,同步和异步。就上图而言,步骤是这样的
同步
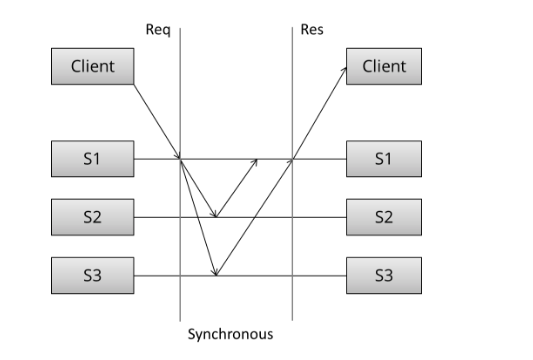
- 客户端发生请求
- 服务器处理请求
- 返回客户端结果
优点:
- 强大的持久性保证(strong durability guarantee)
缺点:
- 系统性能受最慢的服务器影响
- 无法容忍服务器丢失
- 受网络延迟影响大
异步
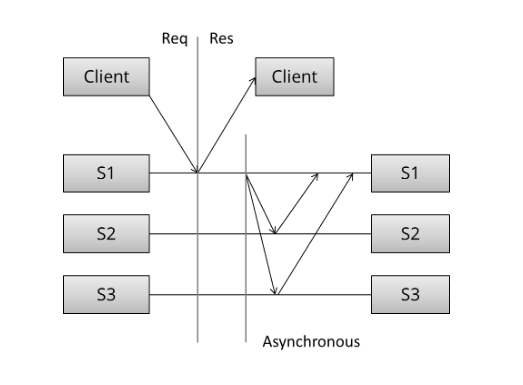
- 客户端发送请求
- 返回客户端结果
- 服务器处理请求
优点:
- 可以容忍网络分区和网络延迟
- probabilistic durability guarantees
缺点:
- 无法保证所有节点数据一致
- 保持可用性
复制算法
复制算法有很多分类标准
- 同步或者异步
- single copy system或者multi-master systems single copy system 能够避免数据分歧,而multi-master system则有可能造成数据分歧。
single copy system behave like a single system, even if parts of node failed. 但是系统可以确保只有一份数据是可用的,并且这份数据是得到了大多数节点的认可。这里其实有一个共识问题。
维持单拷贝一致性的复制算法有:
- 1n message(异步主从备份)
- 2n message(同步主从备份)
- 4n message(两阶段提交,multi-paxos)
- 6n message(三阶段提交,Paxos with repeated leader election)
主从复制
一般在primary做更新,之后将log数据发送到从库更新
mysql和mongoDB都是用异步主从备份。异步主从比同步主从一致性强度要低,但同步主从复制也有问题,假设:
- primary 收到一个写请求并且把它发送到从库
- 从库把这个请求持久化后并响应
- 然后主库在更新之前失败 如果是这样的情景,数据不一致,就只能人为手动干预。
两阶段提交
在第一阶段,coordinator会发送更新数据给参与者,参与者投票是否更新,若决定更新,则将更新数据放在一个临时空间 在第二阶段,当coordinator收到所有参与者的投票且所有参与者都要更新,则向所有参与者发送确认更新的消息,参与者就将更新数据从临时空间移走,并更新。否则回滚。 两阶段提交比主从要强,因为它至少能容错了,但是对于分区容错,它其实无能为力。
分区容错一致性算法
首先区分了节点失灵和网络分区,然后主要以raft为例讲了下机制
小结
